KeyRelBERT
by Aman Priyanshu
Introduction
In this blog post, we will introduce KeyRelBERT, a novel approach for keyword extraction and relation extraction that builds on KeyBERT’s foundations. KeyRelBERT is designed to extract not only the most relevant keywords and keyphrases from a document but also to identify the relationships between them. It is a streamlined pipeline for keyword extraction and relation extraction technique that leverages SentenceTransformers embeddings to expand keyword extraction & employs unsupervised similarity computation for relation extraction.
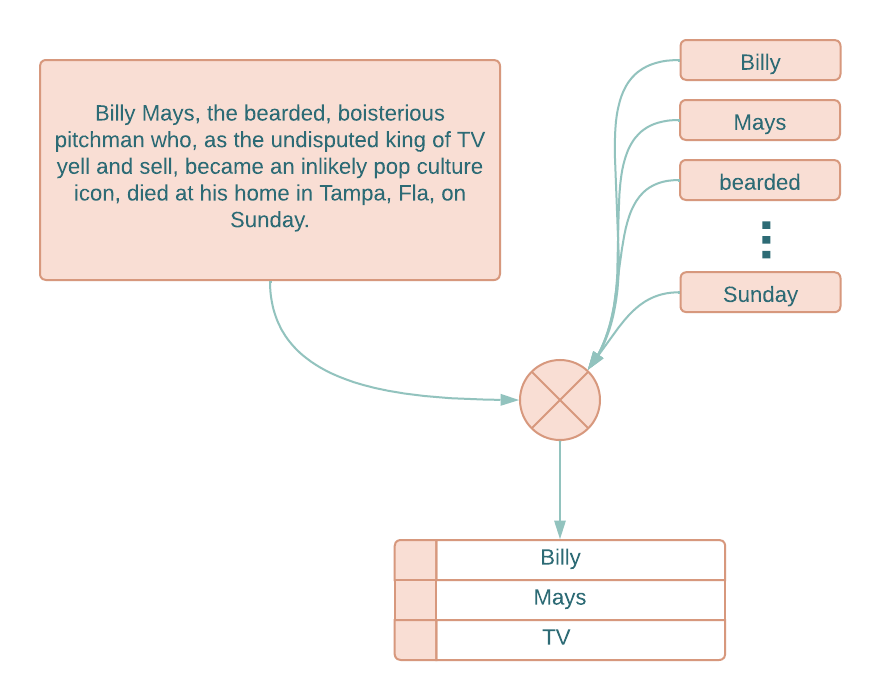
Keyword Extraction
Keyword extraction is an NLP task that involves the automated detection of primary/most important words or phrases in a given sentence or document. The primary objective of keyword extraction is to extract a small set of words or phrases that capture the essence of a document’s content. It is commonly used in various NLP applications such as text classification and information retrieval.
Keyword extraction techniques can be broadly classified into two categories: supervised and unsupervised. KeyBERT employs an unsupervised approach towards keyword extraction by comparing and ranking candidate word embeddings against the document embeddings.
Relation Extraction
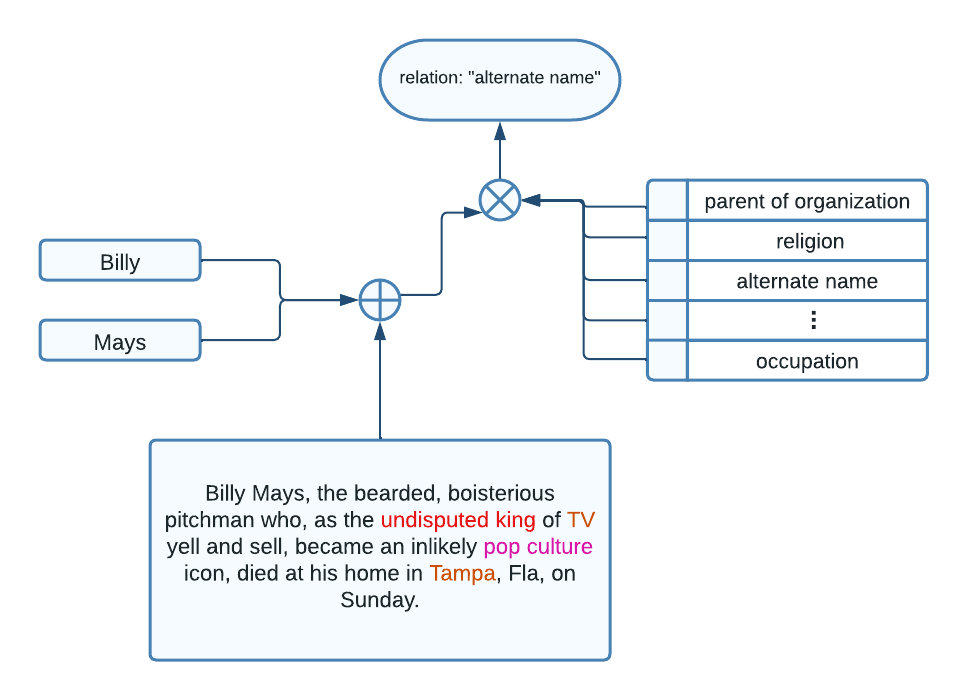
Relation extraction is a natural language processing task that involves identifying and extracting semantic relationships between entities mentioned in text. The goal of relation extraction is to extract structured information from unstructured text by identifying the relationships between entities such as people, organizations, and locations. It can be used for question-answering, chatbots, and even knowledge-base construction.
This project aims to introduce an unsupervised methodology for relation extraction building atop the KeyBERT framework.
Tech Stack
KeyRelBERT relies on several key open-source frameworks to perform keyword and relation extraction.
- KeyBERT: is an easy-to-use keyword extraction technique that leverages LLM embeddings to extract keywords and keyphrases that are most similar to their original document.
- SentenceTransformers: is a Python library for SOTA sentence, text, and image embeddings.
Proposed Methodology:
The proposed methodology for KeyRelBERT involves two main steps:
-
Keyword Extraction: KeyRelBERT uses KeyBERT to extract the most relevant keywords and keyphrases from a document, in this step. KeyBERT works by computing the cosine similarity between each sentence in a document and a set of candidate keywords or keyphrases. The candidate keywords or keyphrases with the highest average similarity scores across all sentences are selected or a marginal relevance-based re-ranking metric may also be used to ensure very similar keywords aren’t extracted.
-
Relation Extraction: In this step, KeyRelBERT employs gradient extraction by backpropagating over two selected keywords/phrases. This allows KeyRelBERT to extract those words which are semantically closer to the two entities between which we require a relation. These are then encoded, and the vectors are compared against potential relation embeddings taken from the
TACRED,NYT,andCoNLL04datasets. Cosine similarity is again used for comparison and eventual selection of relations between the two entities.
Implementation
KeyRelBERT modifies KeyBERT in the following code-bases.
Word-Level Gradient Extraction:
Aims to extract word-level gradients upon backpropagation given a specified embedding vector: w_embedding. We can extract this from the SentenceTransformer’s submodule - 0.auto_model.embeddings.word_embeddings.
However, due to the model.embed() executing with torch.no_grad() the function is manually replicated to return the gradients.
def backpropogate_and_get_words(self, docs, w_embedding):
self.model.embedding_model.zero_grad()
word_embedding_layer = self.model.embedding_model.get_submodule('0.auto_model.embeddings.word_embeddings')
output = self.model.embed(docs, return_detached=True)[0]
single_word_embeddings = output['sentence_embedding']
input_ids = output['input_ids']
loss = self.criterion(single_word_embeddings, w_embedding, torch.tensor(1))
loss.backward()
gradients = word_embedding_layer.weight.grad
gradients = torch.index_select(gradients, 0, input_ids)
gradients_columnar = torch.mean(gradients, 1), torch.std(gradients, 1)
gradients = gradients.transpose(0, 1)
gradients = (gradients - gradients_columnar[0])/gradients_columnar[1]
gradients = gradients.transpose(0, 1)
scores = torch.sum(torch.abs(gradients), 1).numpy()
input_ids = input_ids.numpy()
sorted_indices = np.argsort(scores)[::-1]
ranked_scores = scores[sorted_indices]
thr_index = len([i for i in ranked_scores if i>ranked_scores[0]-np.std(scores)/1.5])
sorted_indices = sorted_indices[:thr_index]
ranked_ids = input_ids[sorted_indices]
ranked_ids_ = []
for r in ranked_ids:
if r not in ranked_ids_:
ranked_ids_.append(r)
return ranked_ids_
Relation Extraction:
Extracting relation based on the proposed methodology, by pooling embedding vectors between two entities word_a and word_b.
ranked_ids = self.backpropogate_and_get_words(docs, (w_embedding_a+w_embedding_b)/2)
competent_words = " ".join([w for w in self.model.embedding_model.tokenizer.convert_ids_to_tokens(ranked_ids) if w not in string.punctuation])
Get subphrase embeddings:
subset_a = word_a+" "+competent_words+" "+word_b
subset_b = word_b+" "+competent_words+" "+word_b
subset_embeddings = self.model.embed([subset_a, subset_b])
Similarity Extraction
similarities_a = torch.nn.functional.cosine_similarity(subset_a, relation_sent, dim=1).numpy()
similarities_b = torch.nn.functional.cosine_similarity(subset_b, relation_sent, dim=1).numpy()
relation_a = self.relations[np.argmax(similarities_a)]
relation_b = self.relations[np.argmax(similarities_b)]
Usage
A basic example can be seen below for keyword extraction and relation extraction:
from keyrelbert import KeyRelBERT
doc = """
Billy Mays, the bearded, boisterious pitchman who, as the undisputed king of TV yell and sell, became an inlikely pop culture icon, died at his home in Tampa, Fla, on Sunday.
"""
keyphrase_extractor = KeyRelBERT()
keyphrase_ngram_range=(1, 2)
doc_embeddings, word_embeddings = keyphrase_extractor.extract_embeddings(doc, keyphrase_ngram_range=keyphrase_ngram_range)
kw_score_list = keyphrase_extractor.extract_keywords(doc,
keyphrase_ngram_range=keyphrase_ngram_range,
doc_embeddings=doc_embeddings,
word_embeddings=word_embeddings,
use_mmr=True,
top_n=10,
diversity=0.6,
)
relations = keyphrase_extractor.extract_relations(doc,
keywords=kw_score_list,
doc_embeddings=doc_embeddings,
word_embeddings=word_embeddings,
keyphrase_ngram_range=keyphrase_ngram_range,
)
print(relations)
Results:
{'billy mays:|:pitchman undisputed': 'cast member', 'pitchman undisputed:|:billy mays': 'original network', 'billy mays:|:icon died': 'date of death', 'icon died:|:billy mays': 'date of death', 'billy mays:|:bearded boisterious': 'mouth of the watercourse', 'bearded boisterious:|:billy mays': 'mouth of the watercourse', 'billy mays:|:king tv': 'cast member', 'king tv:|:billy mays': 'original network', 'billy mays:|:pop culture': 'influenced by', 'pop culture:|:billy mays': 'genre', 'billy mays:|:yell sell': 'cast member', 'yell sell:|:billy mays': 'capital', 'billy mays:|:inlikely': 'residence', 'inlikely:|:billy mays': 'residence', 'billy mays:|:tampa fla': 'headquarters location', 'tampa fla:|:billy mays': 'located in or next to body of water', 'billy mays:|:sunday': 'cast member', 'sunday:|:billy mays': 'city of residence', 'pitchman undisputed:|:icon died': 'followed by', 'icon died:|:pitchman undisputed': 'cause of death', 'pitchman undisputed:|:bearded boisterious': 'performer', 'bearded boisterious:|:pitchman undisputed': 'subsidiary', 'pitchman undisputed:|:king tv': 'original language of work', 'king tv:|:pitchman undisputed': 'original language of work', 'pitchman undisputed:|:pop culture': 'top members', 'pop culture:|:pitchman undisputed': 'genre', 'pitchman undisputed:|:yell sell': 'major shareholder', 'yell sell:|:pitchman undisputed': 'followed by', 'pitchman undisputed:|:inlikely': 'headquarters location', 'inlikely:|:pitchman undisputed': 'followed by', 'pitchman undisputed:|:tampa fla': 'major shareholder', 'tampa fla:|:pitchman undisputed': 'production company', 'pitchman undisputed:|:sunday': 'performer', 'sunday:|:pitchman undisputed': 'publication date', 'icon died:|:bearded boisterious': 'cause of death', 'bearded boisterious:|:icon died': 'mouth of the watercourse', 'icon died:|:king tv': 'cause of death', 'king tv:|:icon died': 'series', 'icon died:|:pop culture': 'date of death', 'pop culture:|:icon died': 'genre', 'icon died:|:yell sell': 'replaced by', 'yell sell:|:icon died': 'followed by', 'icon died:|:inlikely': 'cause of death', 'inlikely:|:icon died': 'instance of', 'icon died:|:tampa fla': 'date of death', 'tampa fla:|:icon died': 'location', 'icon died:|:sunday': 'cause of death', 'sunday:|:icon died': 'publication date', 'bearded boisterious:|:king tv': 'head of government', 'king tv:|:bearded boisterious': 'original network', 'bearded boisterious:|:pop culture': 'ethnic group', 'pop culture:|:bearded boisterious': 'genre', 'bearded boisterious:|:yell sell': 'performer', 'yell sell:|:bearded boisterious': 'shareholders', 'bearded boisterious:|:inlikely': 'mouth of the watercourse', 'inlikely:|:bearded boisterious': 'instance of', 'bearded boisterious:|:tampa fla': 'residence', 'tampa fla:|:bearded boisterious': 'residence', 'bearded boisterious:|:sunday': 'operator', 'sunday:|:bearded boisterious': 'operator', 'king tv:|:pop culture': 'official language', 'pop culture:|:king tv': 'genre', 'king tv:|:yell sell': 'replaced by', 'yell sell:|:king tv': 'replaced by', 'king tv:|:inlikely': 'followed by', 'inlikely:|:king tv': 'followed by', 'king tv:|:tampa fla': 'followed by', 'tampa fla:|:king tv': 'followed by', 'king tv:|:sunday': 'cast member', 'sunday:|:king tv': 'relative', 'pop culture:|:yell sell': 'record label', 'yell sell:|:pop culture': 'owned by', 'pop culture:|:inlikely': 'ethnic group', 'inlikely:|:pop culture': 'operator', 'pop culture:|:tampa fla': 'genre', 'tampa fla:|:pop culture': 'located in or next to body of water', 'pop culture:|:sunday': 'genre', 'sunday:|:pop culture': 'publication date', 'yell sell:|:inlikely': 'mouth of the watercourse', 'inlikely:|:yell sell': 'mouth of the watercourse', 'yell sell:|:tampa fla': 'owned by', 'tampa fla:|:yell sell': 'continent', 'yell sell:|:sunday': 'dissolved, abolished or demolished', 'sunday:|:yell sell': 'date of death', 'inlikely:|:tampa fla': 'followed by', 'tampa fla:|:inlikely': 'followed by', 'inlikely:|:sunday': 'point in time', 'sunday:|:inlikely': 'publication date', 'tampa fla:|:sunday': 'headquarters location', 'sunday:|:tampa fla': 'publication date'}
Conclusion
I hope this methodology for relation extraction is useful for shorter-scale NLP projects.
Check out the Twitter Post at:
Subscribe via RSS